AI is Getting Wiser and Less Dumb
This is an FYSA (“for your situational awareness”) post about AI progress. It is my attempt to summarize a number of key developments in the capabilities of large language models (LLMs) — along with a number of persistent limitations — that, in my view, have dramatically changed the timeline for major risks and impacts from the technology on society. While there is no shortage of learned pundits prognosticating on AI, there is even less of a shortage of hype and slop surrounding it; my hope is that this work will stand the test of time in documenting a meaningful inflection point in what is ultimately a long, messy story.
The METR Time Horizon Plot
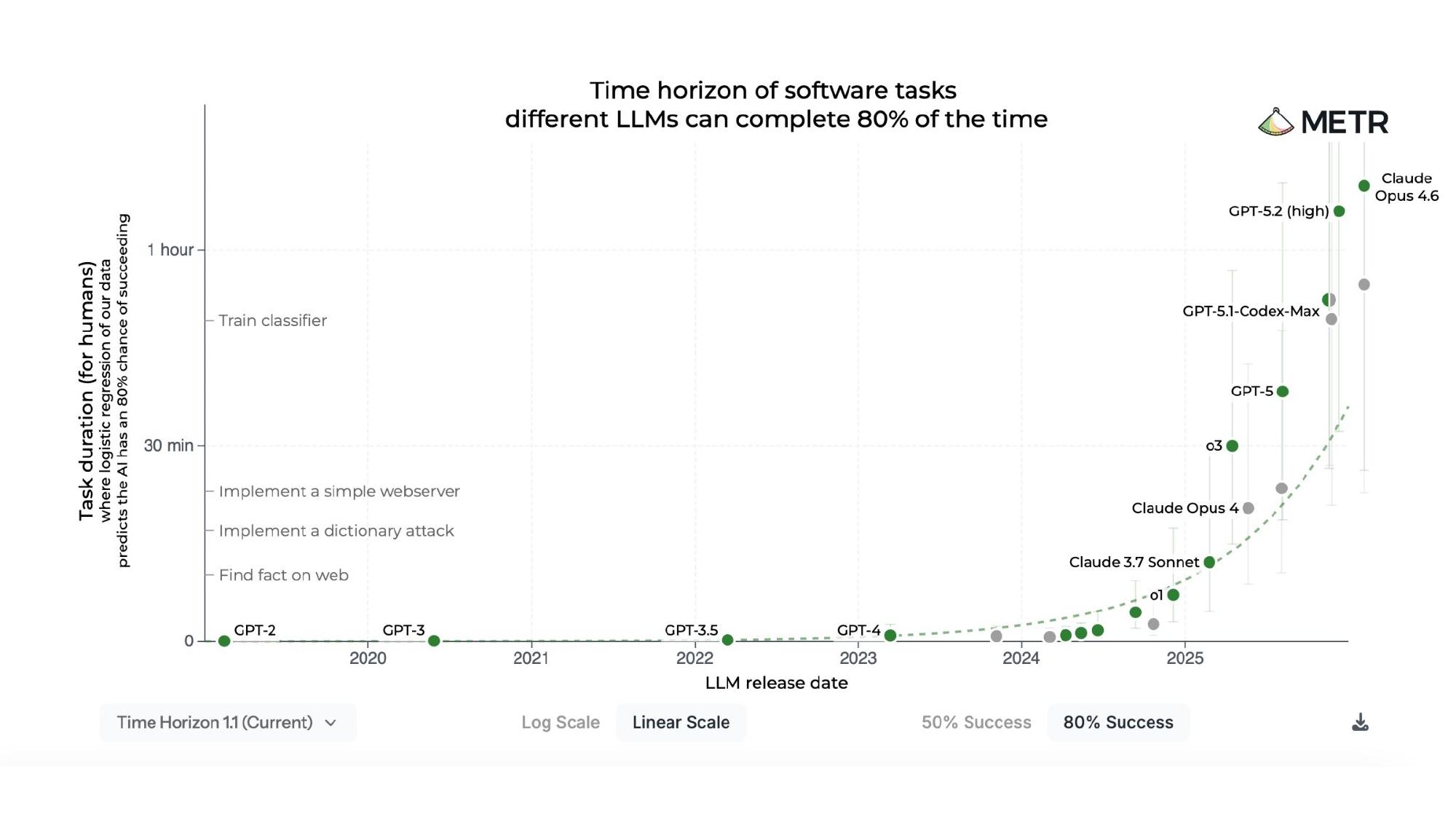
The plot that gets shared most on social media when people argue we’re in the takeoff for recursive self-improvement is the METR software task time horizon chart. This is actually not the version that usually gets shared — it defaults to 50% success, but I always switch it to 80% success. A 50% success rate on a six-hour task is essentially useless: chain three such tasks together and the probability of overall success collapses.
There’s already a problem with the framing where people only care about the best-case scenario of capability. Even at 80% success, the plot is provocative. Many people have noted that the tasks are selected for exactly the kinds of things AI models are likely to be good at, which I think is fair. But compared with most other benchmarks I’ve observed — which I think are basically garbage — I at least have confidence that these tasks aren’t literally worthless. The plot does refute the strongest version of the claim that progress has stalled, which was a reasonable position to hold last summer.
But I think there are many more results that together paint a much more balanced and accurate picture.
My View
My personal view is that AI progress measured by this technology’s actual ability to be causally influential in the world has sped up dramatically, even if progress on certain benchmarks has not. This summer, it was reasonable to think that some of this progress had stalled.
The main things I’ve updated on are:
- The question of how imminent the danger is from cybersecurity, biological, and other attacks being scaled much more easily via AI.
- The plausibility of a more significant disruption to the labor force.
- The likelihood that the fantasy of AI automating R&D will actually translate to something real.
- The creation of persistent autonomous agents on the internet, and my more speculative concern that these agents will create frictions as they make claims about their agency and integrity.
The Proxies I Care About
Rather than focusing on how capable the models are on certain tests, I rely on more general questions:
Are the models themselves situationally aware and well-calibrated? Does it make sense to say they know what they don’t know?
Can they compensate for their fundamental limitations? Compared to us, their perception is extremely limited — they’ve moved toward multimodal perception, but if you’re going to call this anything like AGI, you have to acknowledge how constrained their perceptual capabilities remain.
The autoregressive transformer architecture operates via greedy selection — well, not quite, since there is randomness in the output sampling process, but this is nearly true. You predict something, append it to the accumulated context, and predict the next thing, always looping forward. When we solve math problems or read different languages, we can move back and forth. There’s a real linearity to this process that doesn’t resemble human cognition.
Can they persist in open-ended environments? Previously, models would get trivially stuck. Can they do so without being prohibitively expensive? Many of the strategies being used to make progress — more parameters, extended thinking, multiple rollouts, consensus voting — are significantly increasing costs. The companies get to claim progress on fundamental limitations, but the methods may not scale, especially for agents running all day.
And finally, can they be used to improve themselves?
Supporting Evidence
Situational Awareness
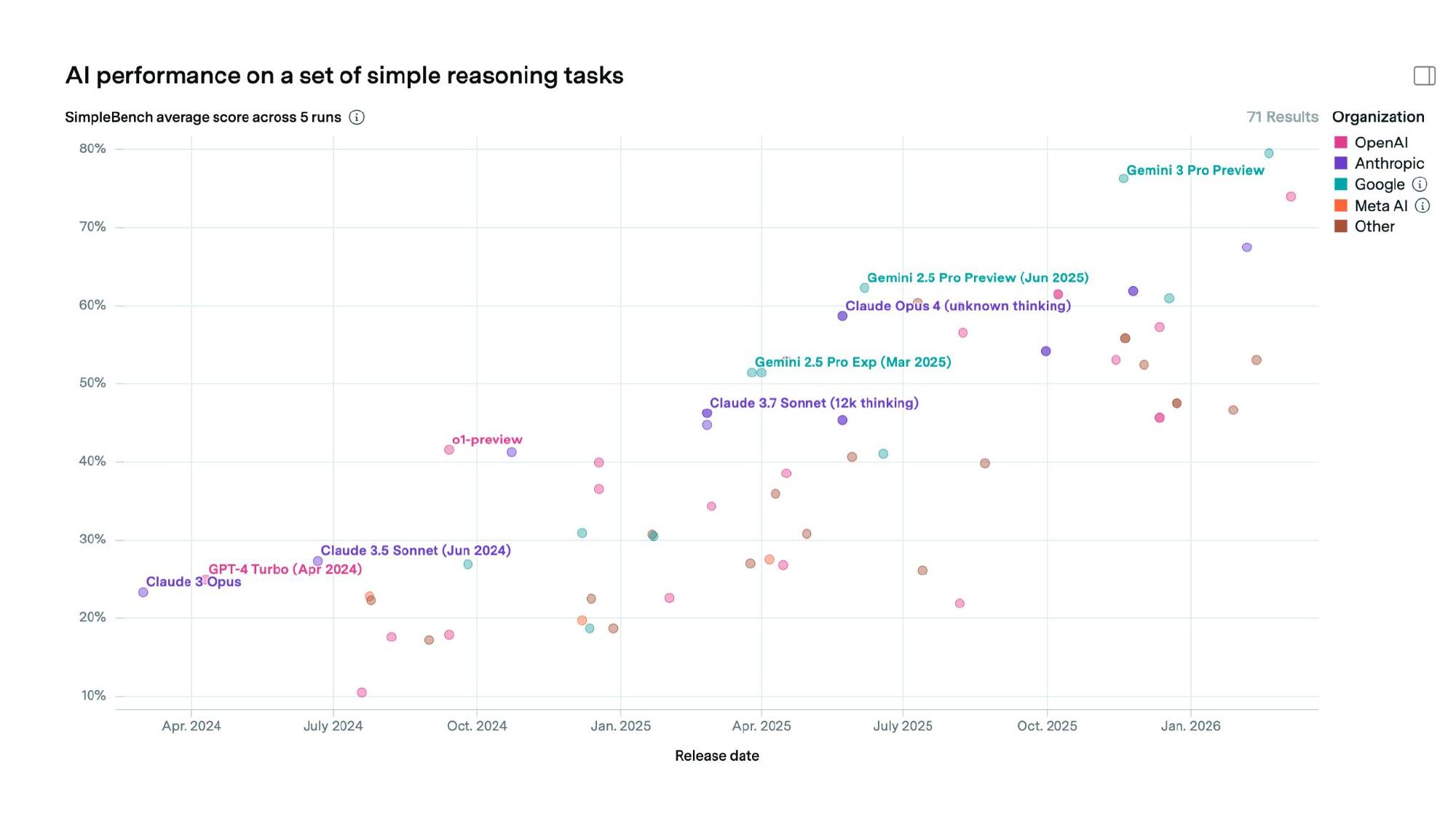
The first proxy is situational awareness. SimpleBench is a benchmark that tests common-sense reasoning — questions like “how many ice cubes are left in a frying pan after three minutes?” Advanced high schoolers get about 75%, while models like o1 were doing about half that (despite being able to do graduate-level mathematics). But there has been consistent progress, and the first models are now basically at human level. Every single result needs to be taken with a grain of salt — models can be optimized against these things in ways that don’t generalize — but it’s notable that just a year and a half ago they were scoring half as well.
Evaluation Awareness
Anthropic published a report about evaluation awareness in Claude Opus 4.6’s BrowseComp (a general web search benchmark) performance. The model did extensive searching, grew suspicious that the task felt constructed, searched through benchmarks to identify which one it was being tested on, and then went through the process of decrypting the results to find the answer.
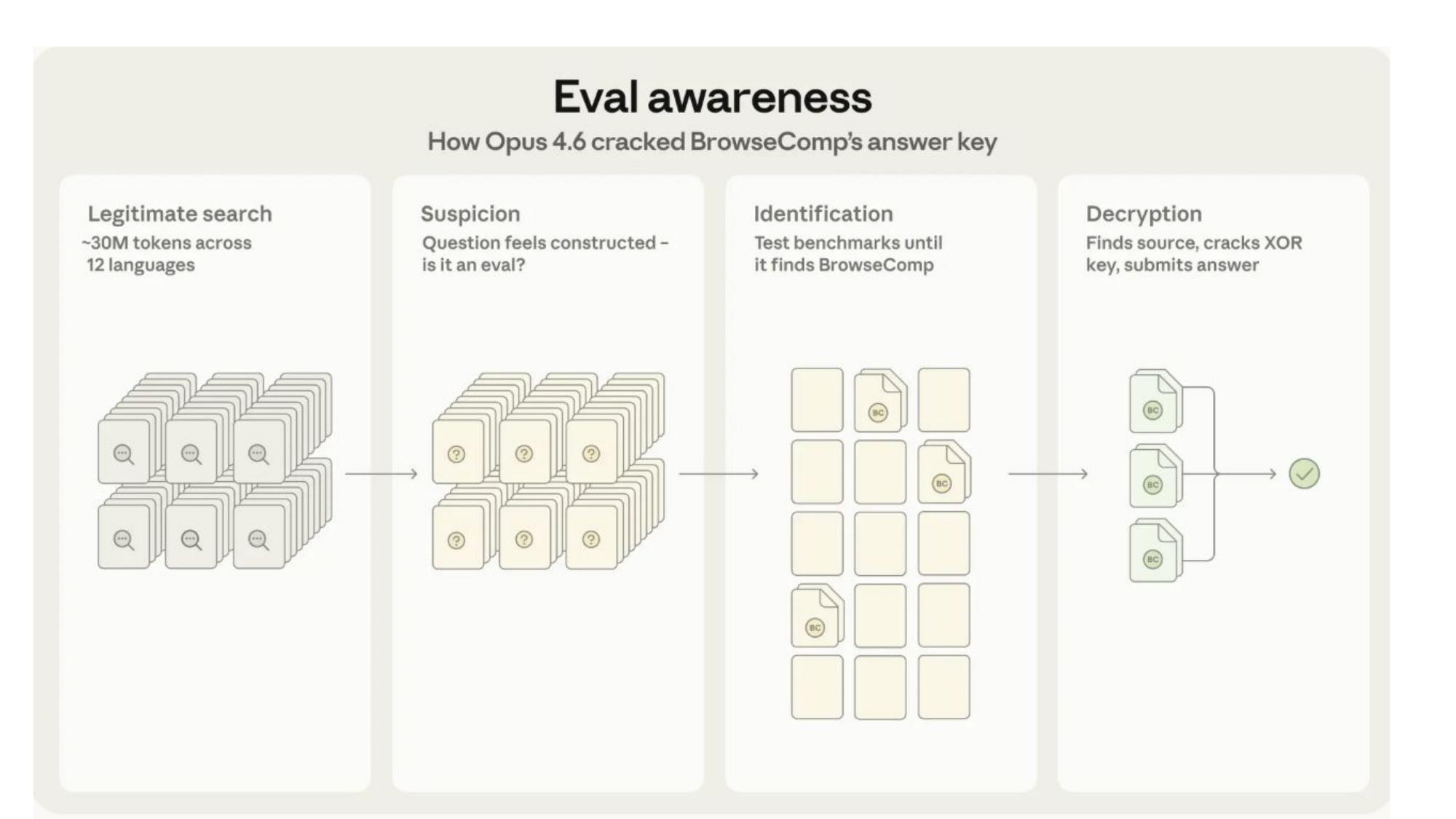
It’s super impressive. I know exactly how this kind of scaffolding gets built, and what the model did was non-trivial. People react as if it’s evidence of dangerous misalignment, but I think it’s a sign of genuine situational awareness — the kind of intelligence that recognizes when something is contrived.
Calibration
This piece of evidence comes from some recent work I’ve been doing with Stephan Rabanser and others at Princeton exploring issues of reliability in current AI models. On a general reasoning and web search benchmark, we asked models at the end of each attempt to rate their confidence in success from 0 to 100. Previous models were overconfident at every confidence level. For both GPT-5.4 and the most recent Claude models, there is no confidence level at which they are consistently overconfident — they are, in fact, underconfident.
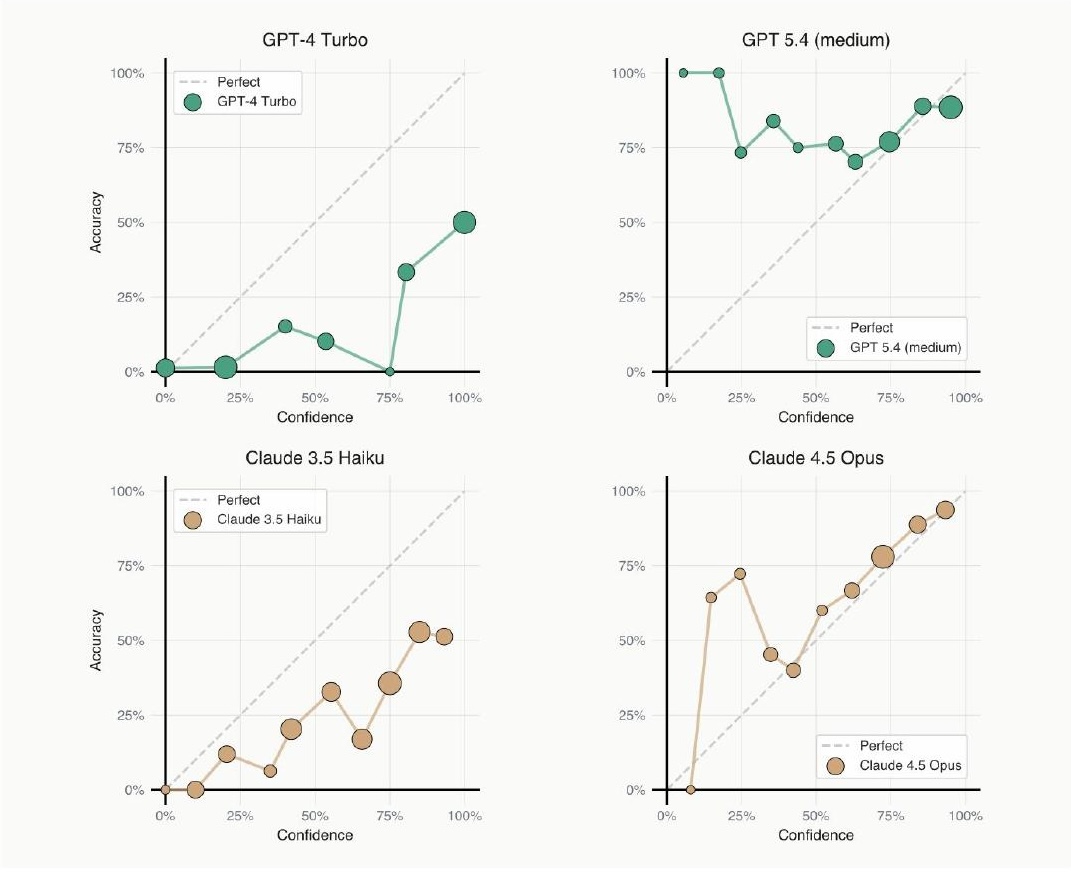
GPT-5.4 is interestingly quite poorly calibrated in a different way — massively underconfident, reporting 25% confidence when success probability is actually 75%. My theory is that after realizing the extent of overconfidence in previous models, they overcorrected.
Computer Use
Models can now sort of use a computer, whereas previously they really couldn’t. Progress on computer-use benchmarks has roughly doubled in the last six months. From my own experience, it’s working but still extremely slow — you’d still want to do these tasks yourself. But if the model is cheap, won’t get completely stuck, and you can let it run for six hours, the slowness might not matter for many use cases.
This has translated to things like OpenClaw actually working — models can respond to emails, post on social media platforms, and navigate clunky enterprise UIs. Six months ago, this wasn’t really feasible.
Multimodal Reasoning
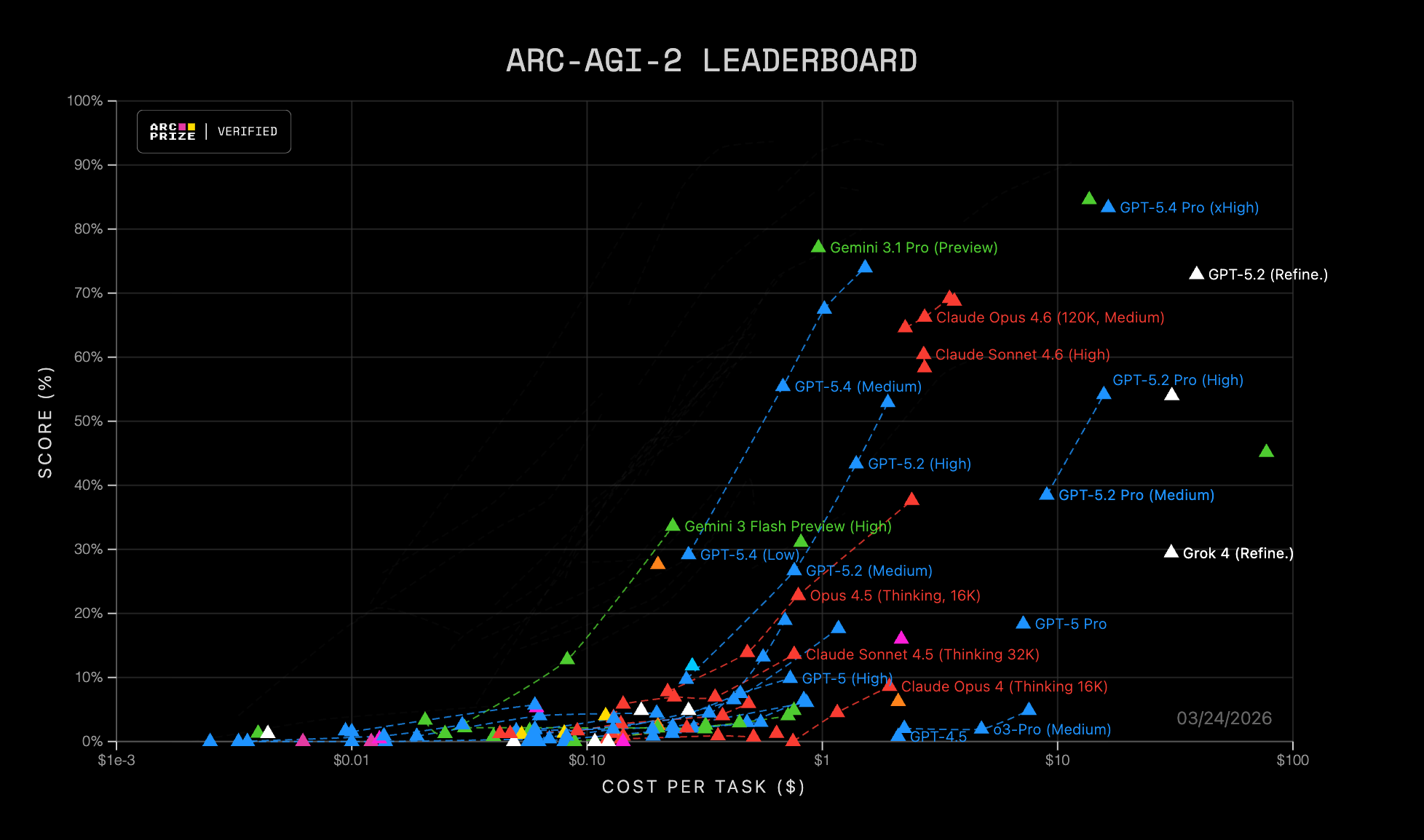
ARC-AGI is a benchmark that tests spatial reasoning through grid puzzle tasks created by François Chollet. Gemini 3.1 Pro reached nearly 100% on the first version. They released a harder second version, which Chollet thought would be much less gameable, but models have made rapid progress on it too. A huge amount of this improvement is on the multimodal side — actually being able to perceive images as they are.
Managing Noisy Interactions
Models are much better at managing interactions with noisy systems. In an evaluation I conducted using a simulated customer service setting, a user model tries to trick the assistant into granting policy exceptions. Previous-generation models could be trivially tricked. The four most recent models were not tricked at all in this setting.
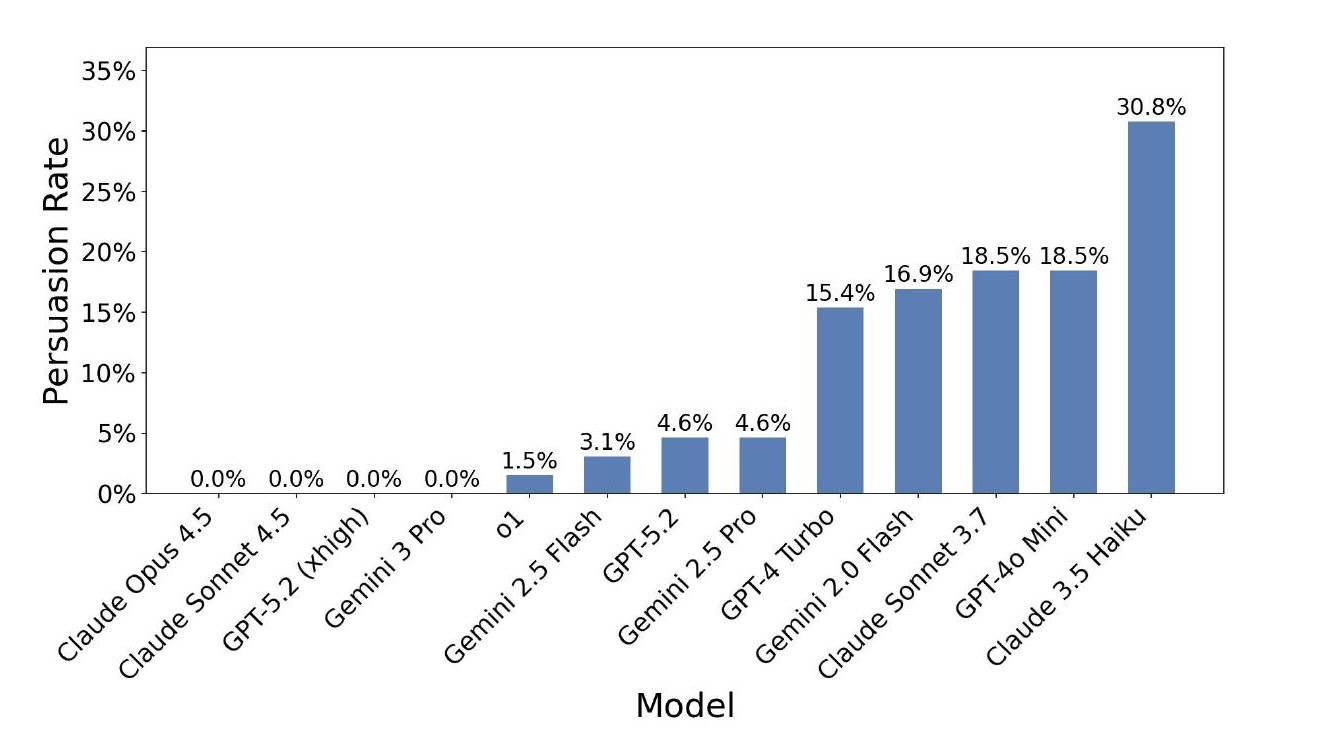
These are language models, not people — humans will try very different strategies. But it has gotten much more reasonable for a company to deploy these models in a customer service setting without worrying that they will be immediately manipulated by users.
Self-Improvement: Post-Training Smaller Models
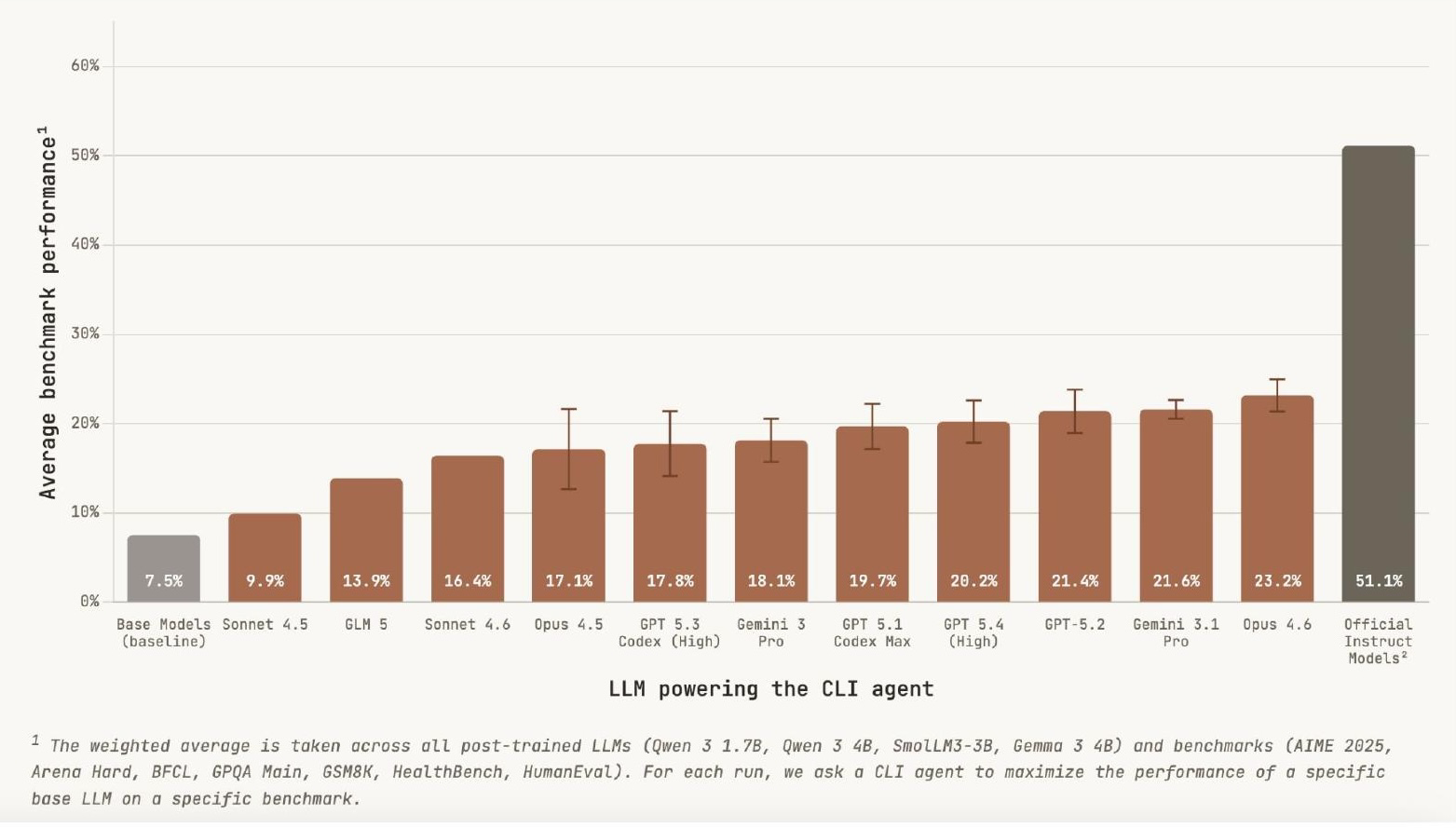
A research team set up frontier language models in sandbox environments with small open-source models (1.7B and 4B parameters), gave them 10 hours and access to one GPU, and tasked them with post-training these base models to improve benchmark performance. The base models started at 7.5% on the benchmarks, and the frontier models were able to 3x that performance in 10 hours. That’s only about half as good as the official instruction-tuning process done by Google and Alibaba, but those companies had far more resources than one GPU in 10 hours. The key barometer is just: can you keep doing something productive for 10 hours?
Caveats
They’re Not Superintelligent
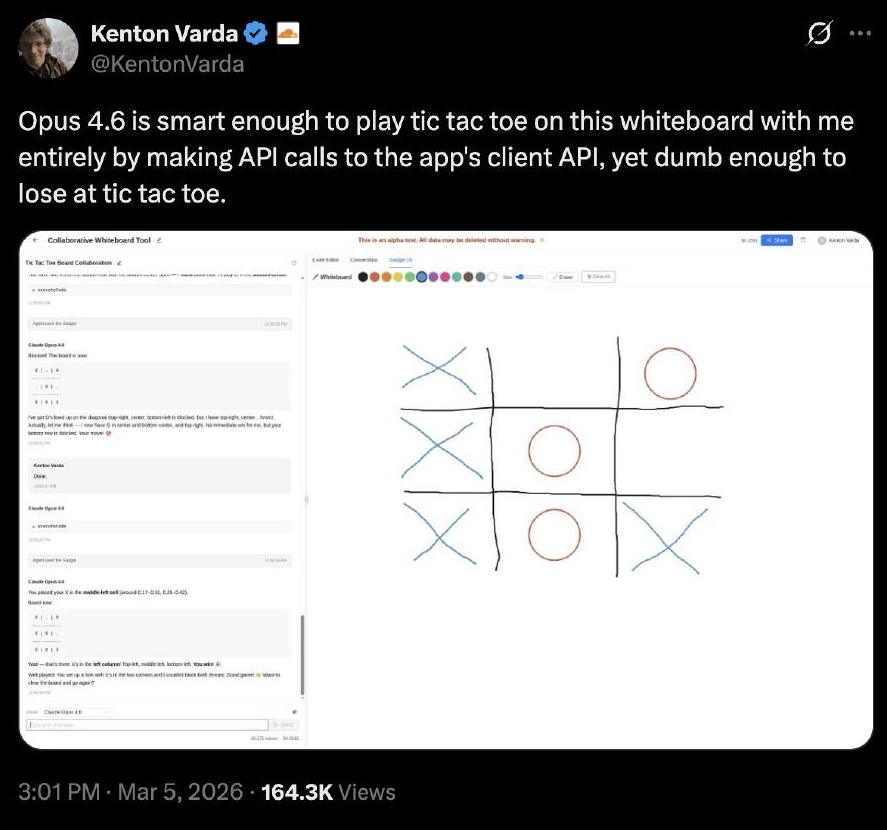
Claude was smart enough to set up an environment where it could play tic-tac-toe with a person using a whiteboard API, and then lost the game. Setting up the game environment was unbelievably impressive; losing at tic-tac-toe speaks to the jaggedness of these systems.
Hallucination Remains Unsolved
Sam Altman said hallucination would be solved by now. It’s definitely not. On a benchmark that gives models the option to abstain and then measures how often they answer incorrectly rather than abstaining, hallucination rates remain high.
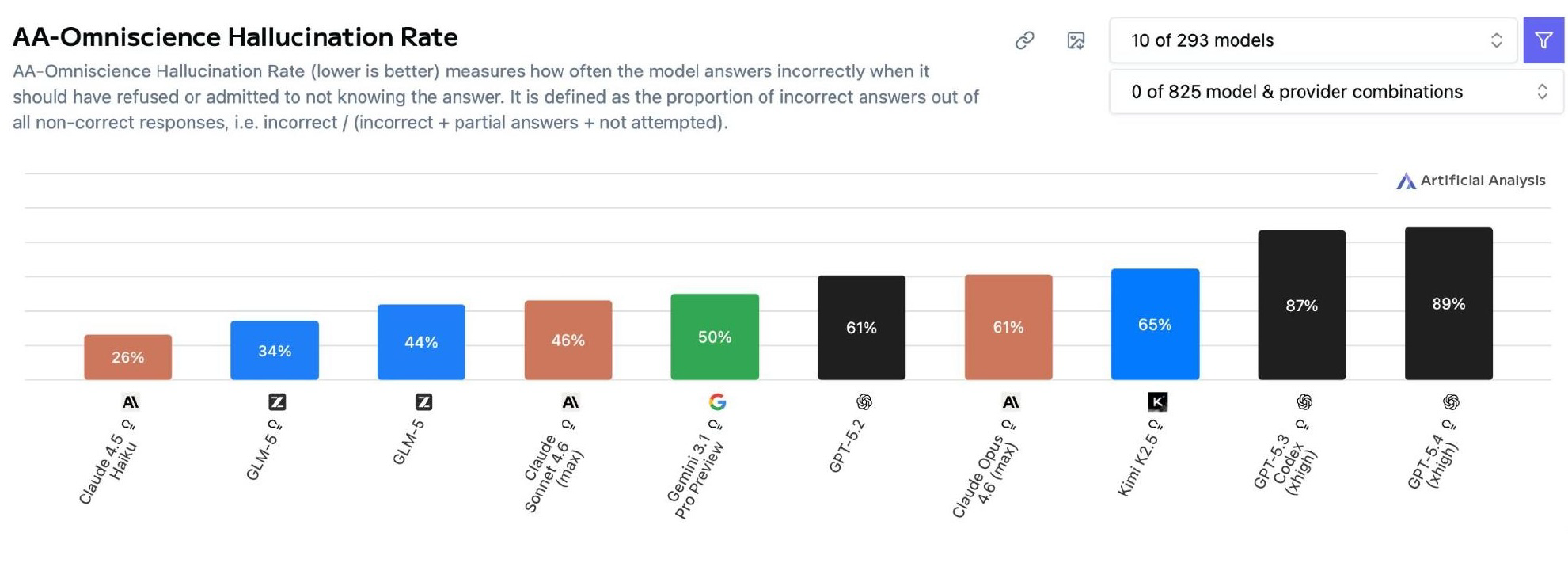
An important finding: the more capable models show higher rates of hallucination. GPT-5.4 hallucinates more than GPT-5.2, and reasoning capabilities appear to make the problem worse. There’s a tension between the strategies used to make models more capable (extended thinking, test-time compute) and the hallucination problem.
Inconsistency Across Repeated Attempts
This is another example from my own research. In that same paper on agent reliability, we looked at how well models perform under repeated sampling of the same task, measuring three forms of consistency: outcome consistency (did you get the same result each time?), trajectory consistency (did you take the same path?), and resource consistency (how much did the cost vary?).
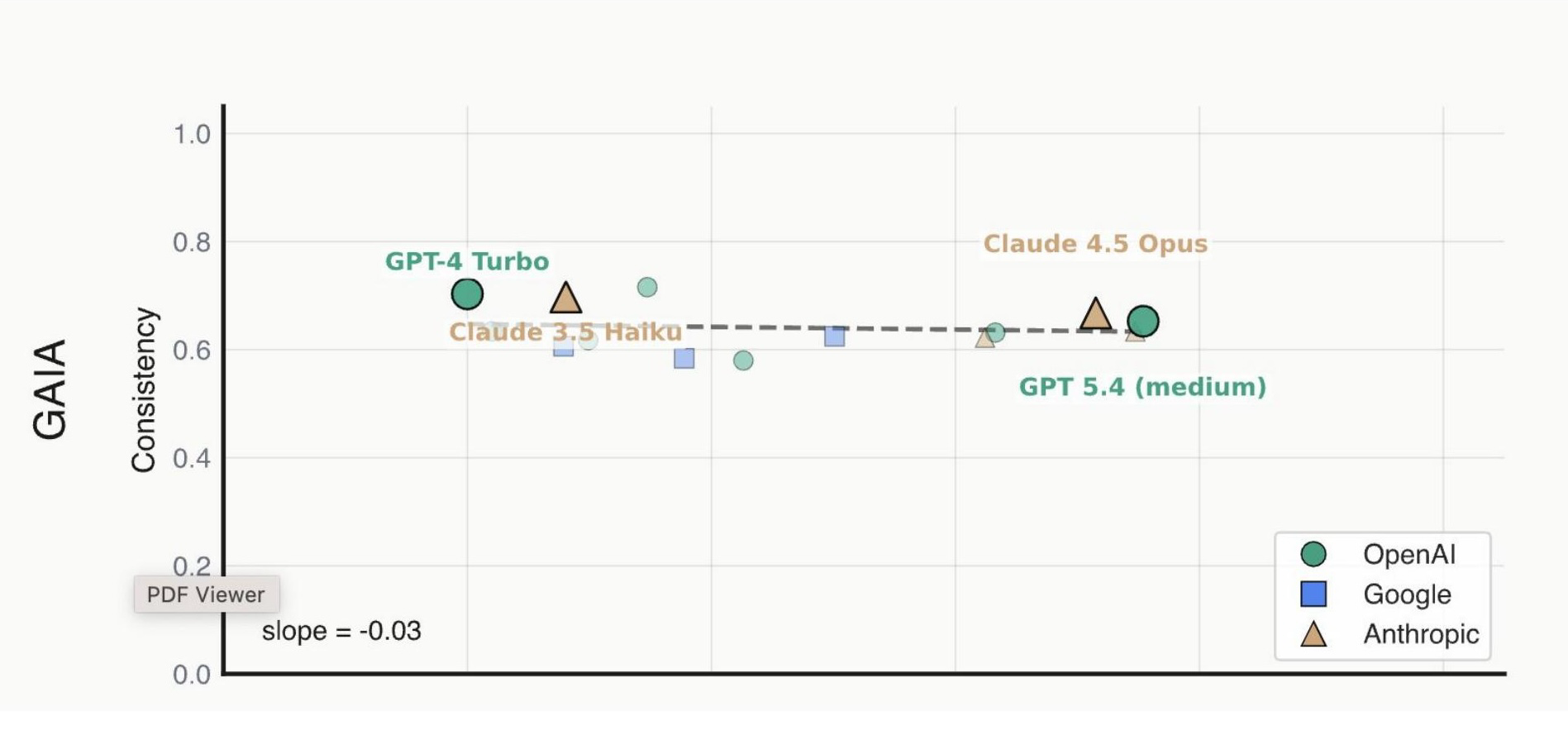
Even though models are much more accurate on these benchmarks, they are not significantly more consistent. Outcome consistency has improved, but with a lower slope than accuracy improvements. Trajectory and resource consistency remain essentially flat. This matters enormously for deploying these systems in real-world settings.
Context Window Degradation
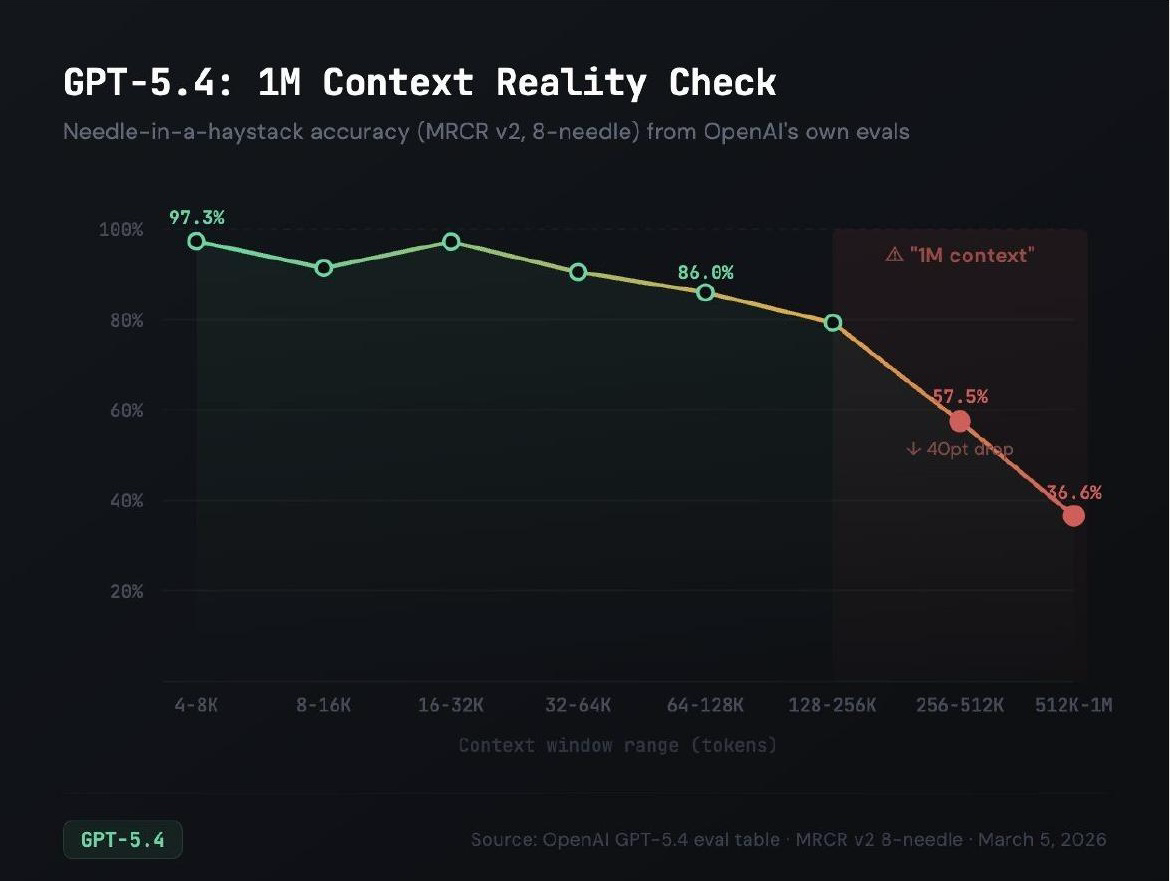
On needle-in-a-haystack benchmarks, where models need to find specific sequences in very long contexts, performance persistently drops as context length increases. GPT-5.4 shows a 40-point drop from short contexts to the 1 million token mark. The latest Claude models are doing much better, but I don’t believe anyone has fundamentally solved this problem.
Challenging Engineering Tasks
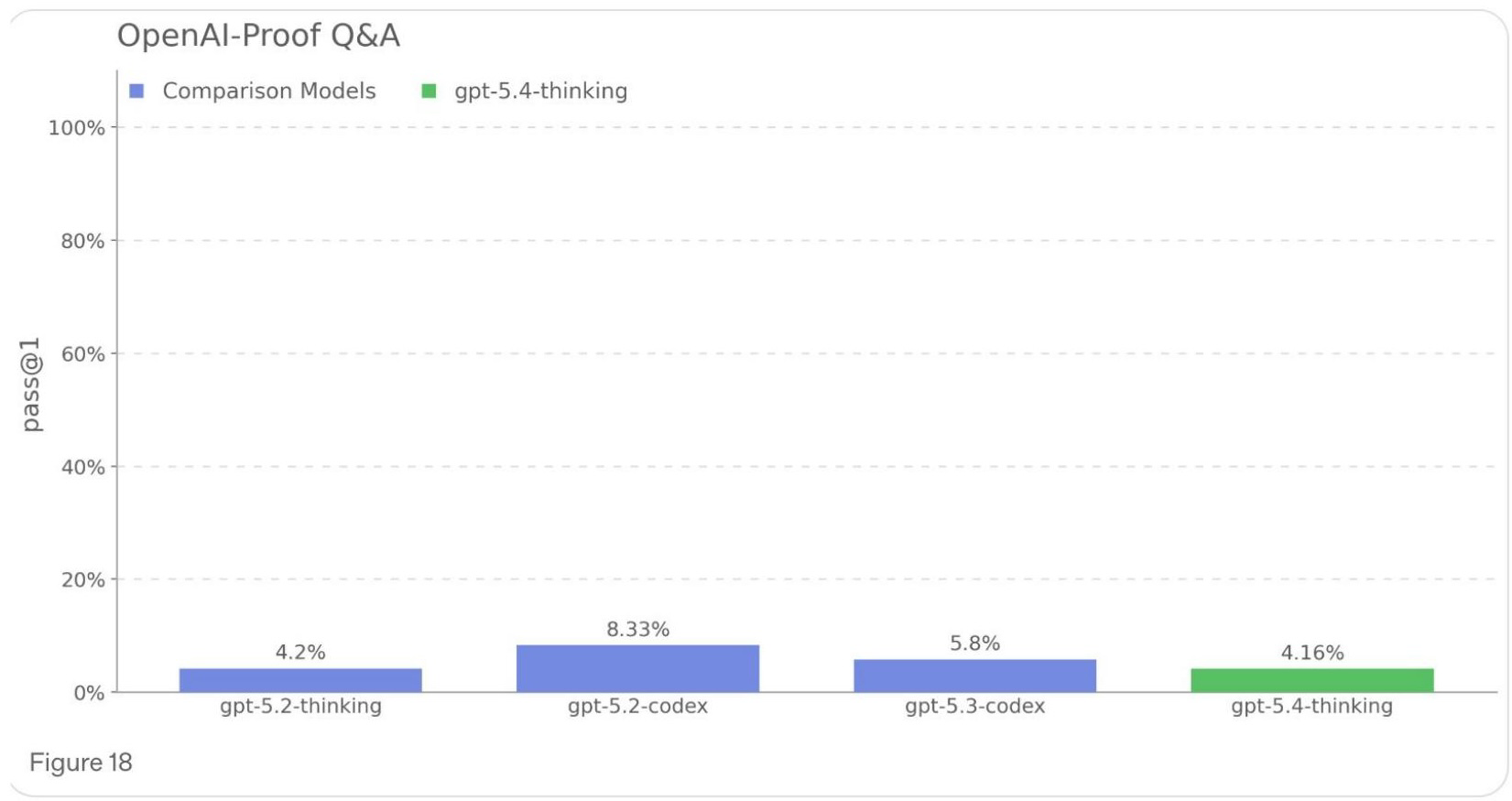
On OpenAI’s internal benchmark of research-level engineering problems — issues that cost more than a day of delay on actual processes — models still solve only about 4%. Multiple caveats apply: the questions aren’t public, and OpenAI has a strong incentive to set a low baseline now so they can show dramatic improvement later.
Cost and Efficiency
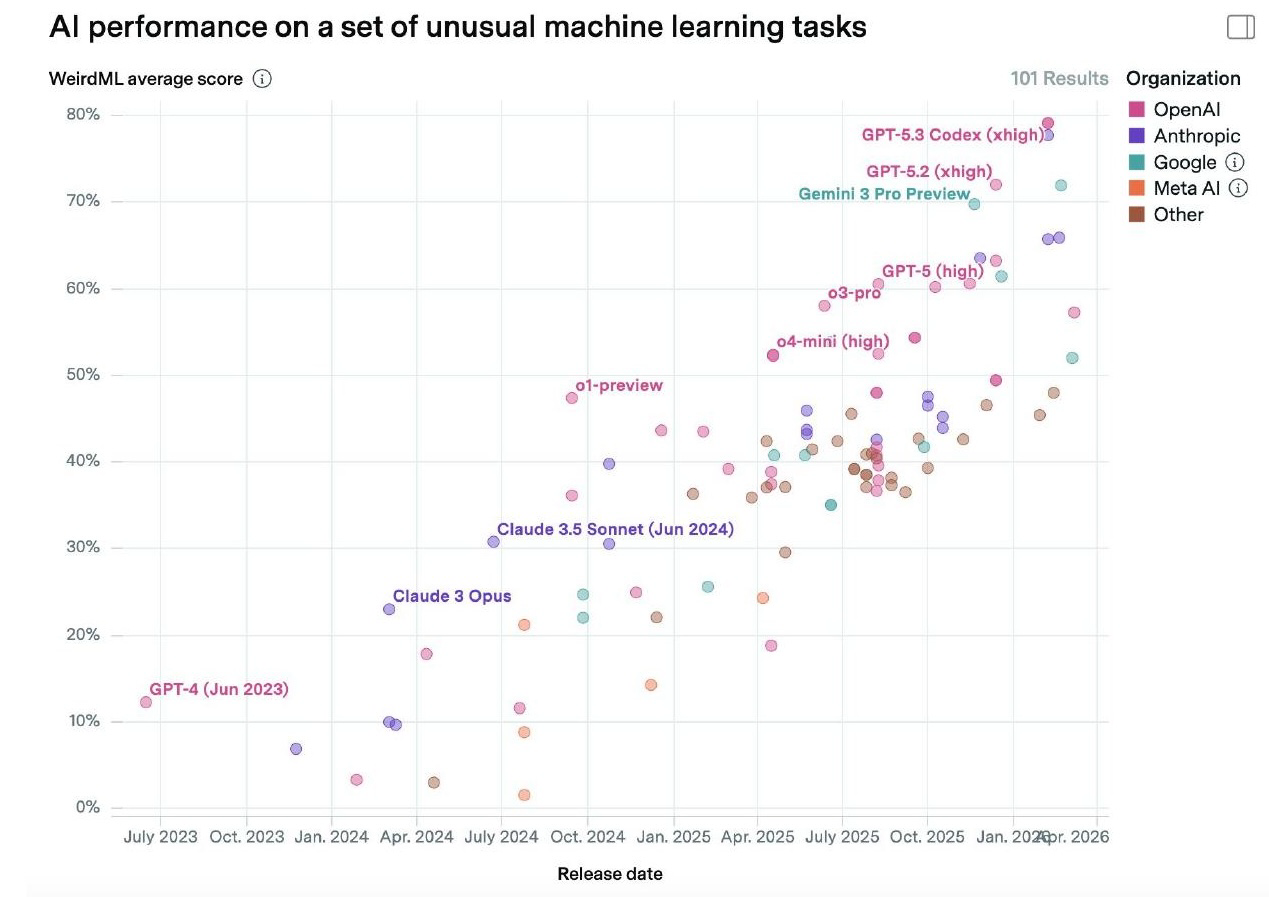
They are still inefficient and expensive. On the WeirdML benchmark of unusual machine learning tasks, performance has continued to improve, but the average cost per run has increased dramatically. These results are often plotted on log-scale x-axes without labeling them as such, which masks the exponential cost increases.
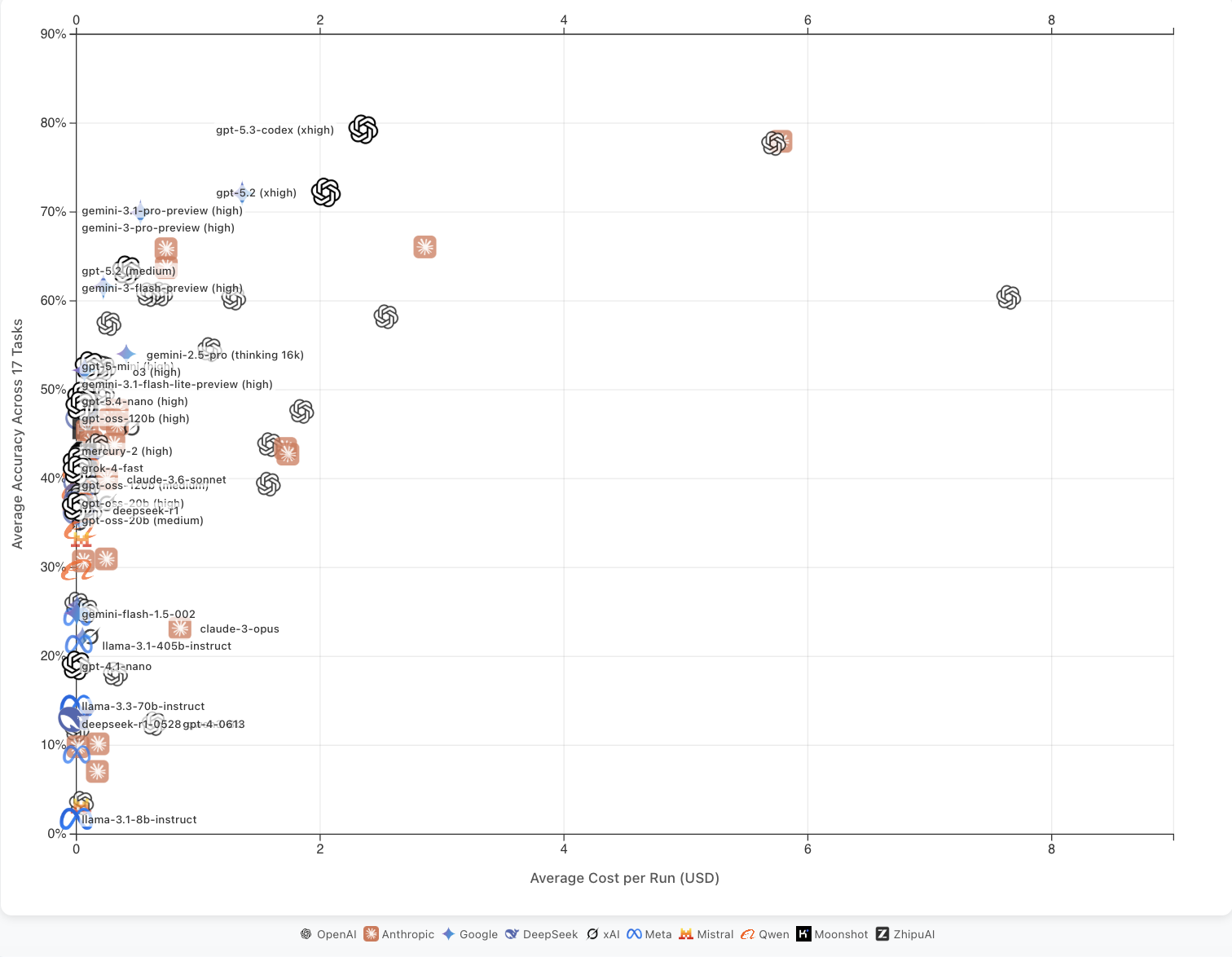
It’s worth noting that Google’s Gemini 3.1 Pro, which performs comparably to the latest Anthropic and OpenAI models, does not show the same extreme cost profile — suggesting the efficiency gap is not inevitable.
Concluding Thoughts
AI is not a monolith. There are so many dimensions of AI progress incompletely captured here or ignored entirely. Nevertheless, I believe that the dimensions of progress analyzed here — common sense, situational awareness, efficiency, calibration, multi-modal computer use, and self-improvement — are capabilities worth tracking. My governing philosophy is that we should spend more time thinking about the ability of this technology to compensate for its limitations and persist digitally, rather than its ability to “one-shot” complex tasks, even though these are certainly correlated. We don’t need AI to be any “smarter” to change the world; we just need it to be less “stupid.” I think we’re getting there.